


 来源:财联社
来源:财联社
编辑 周子意
社交媒体公司推特的现任老板埃隆·马斯克周三(4月19日)指控微软公司非法使用推特的数据来训练其人工智能(AI)模型,还警告要起诉这家软件巨头。
该事件还要从微软的一则“封杀令”开始说起。
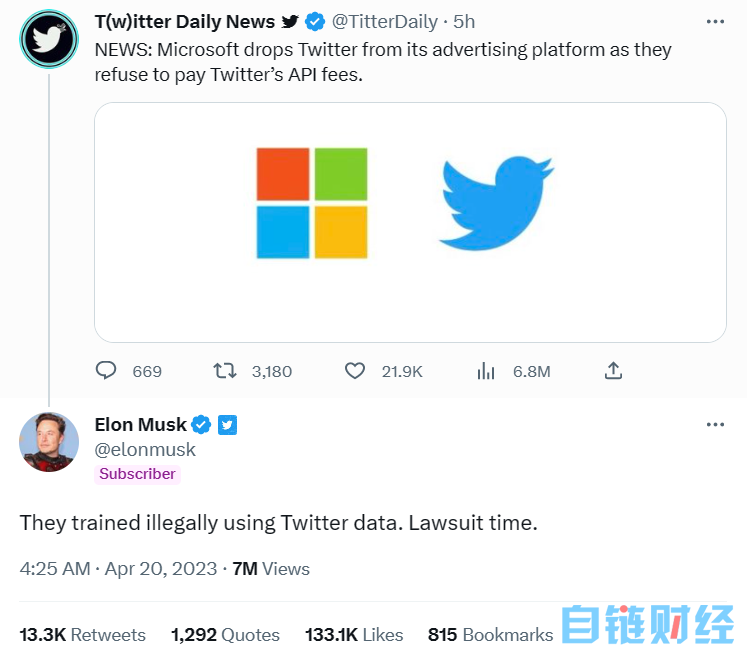
就在马斯克威胁起诉之前,有媒体周三报道称,微软将把推特从其广告平台中移除,微软的这一平台是一个面向广告主的社交媒体规划和调度工具,广告买家能够在该平台管理他们所有的社交媒体账户。
而微软官网上发表声明称,从2023年4月25日开始,该平台将不再支持推特。
随后,马斯克发推道,“他们(微软)非法使用推特数据进行训练,诉讼时间到。”
数据所有权之争
事实上,马斯克的诉讼警告反映了AI领域中的一个趋势,也就是数据所有权正迅速成为生成式人工智能(AIGC)热潮中一个激烈的新“战场”。
随着大型科技公司正在努力开发类似OpenAI公司GPT的尖端AI模型,越来越多的数据所有者试图对AI模型的数据获得收取使用费,从中“薅一把羊毛”。
像GPT这样大型语言模型(LLM)的训练往往需要TB级的海量数据,所以其中一大部分都是从Reddit、StackOverflow、推特等网站上获取的。
来自社交网络的数据对于AI的训练来说很有价值,因为这些社交平台上充斥着各种非正式的、多回合的对话。
不过,随着这些新的AI模型逐步从实验室和大学研究所进入企业界,数据所有者开始向AI开发商提出要求。
“美国贴吧”Reddit本周早些时候表示,将开始向使用其应用程序编程接口(API)的企业收费,该接口则提供了下载和处理人与人之间对话的相关数据。
环球音乐集团(Universal Music Group)也已发出警告,阻止AI服务从其受版权保护的歌曲中抓取旋律和歌词。
此外,知名图库Getty Images正在起诉Stable AI公司的开源AI艺术生成器Stable Diffusion,指控该公司通过复制Getty Images上的内容来训练AI。