

译者:AI研习社(Born alone°)
双语原文链接:NEURAL NETWORKS (MAYBE) EVOLVED TO MAKE ADAM THE BEST OPTIMIZER
免责声明:这篇文章和我平时的有些不同。事实上,我不会证明任何东西,我只是简单地解释一下我关于深度神经网络优化的一些猜想。和我平时的帖子不同,我写的东西完全有可能是错的。
我已经从实践和经验的角度研究在线和随机优化有一段时间了。所以,当Adam (Kingma and Ba, 2015)被提出时,我已经在这个领域了。


这篇论文还可以,但算不上突破,就今天的标准而言更是如此。事实上,这个理论是薄弱的:对于一种应该处理非凸函数随机优化的算法给出了 regret guarantee。这些实验也很弱:在这些日子里,同样的实验肯定会遭到拒绝。晚些时候人们还在证明中发现了一个错误以及该算法不收敛于某些一维随机凸函数的事实。尽管如此,现在 Adam 被认为是优化算法之王。让我明确一点:众所周知, Adam 不会总实现最佳性能, 但大多数时候,人们认为可以利用 Adam 的默认参数在处理某个深度学习问题上实现至少次优的性能。换句话说,Adam 现在被认为是深度学习的默认优化器。那么,Adam 背后成功的秘密是什么?
多年来,人们发表了大量的论文试图解释 Adam 和它的表现,太多了,不能一一列举。从“适应学习率”(适应到什么?没有人确切地知道……)到动量,到几乎标度不变性 ,它的神秘配方的每一个方面都被检查过。然而,这些分析都没有给我们关于其性能的最终答案。很明显,这些成分中的大多数对任何函数的优化过程都是有益的,但仍然不清楚为什么这个确切的组合而不是另一个组合使它成为最好的算法。混合物的平衡是如此的微妙以至于修正不收敛问题所需的小更改被认为比 Adam 表现稍差。
Adam 的名声也伴随着强烈的情感:阅读 r/MachineLearning on Reddit 上的帖子就足以看出人们对捍卫他们最喜欢的优化器的热情。这种热情你可以在宗教、体育和政治中看到。
然而,这一切的可能性有多大?我是说,Adam 是最佳优化算法的可能性有多大?几年前,在一个如此年轻的领域,我们达到深度学习优化的顶峰的可能性有多大?它的惊人表现还有其他的解释吗?
我有一个假设,但在解释之前,我们必须简单谈谈深度学习社区。
在谈话中,Olivier Bousquet 将深度学习社区描述为一个巨人 genetic algorithm:这个社区的研究人员正在以一种半随机的方式探索各种算法和架构的空间。在大型实验中一直有效的东西被保留,无效的被丢弃。请注意,这个过程似乎与论文的接受和拒绝无关:这个社区是如此的庞大和活跃,关于被拒绝论文的好想法仍然会被保存下来,并在几个月内转化为最佳实践,参见举例 (Loshchilov and Hutter, 2019)。类似地,发表的论文中的观点被成百上千的人复制,他们无情地丢弃那些不会复制的东西。这个过程创造了许多启发式,在实验中始终产生良好的结果,这里的重点是“始终如一”。事实上,尽管是一种基于非凸公式的方法,深度学习方法的性能证明是非常可靠的。(需要注意的是,深度学习社区对“名人”也有很大的偏好,所以并不是所有的想法都能得到同等程度的关注……)
那么,这个巨大的遗传算法和亚当之间有什么联系?嗯,仔细观察深度学习社区的创建过程,我注意到一个模式:通常人们尝试新的架构,保持优化算法不变,大多数时候选择的算法是 Adam。如上所述,这是因为 Adam是默认的优化器。
所以,我的假设是:Adam 是一个非常好的神经网络架构的优化算法,我们几年前就有了,人们不断地发展新的架构,让 Adam 在上面工作。因此,我们可能不会看到许多 Adam 不工作的架构,因为这些想法被过早地抛弃了!这样的想法需要同时设计一个新的架构和一个新的优化器,这将是一个非常困难的任务。换句话说,社区只进化了一组参数(架构、初始化策略、超参数搜索算法等),大部分时间优化器都固定在 Adam 身上。
现在,我相信很多人不会相信这个假设,我相信他们会列出各种具体的问题,在这些问题中 Adam 不是最好的算法,在这些问题中 随机梯度下降 动量是最好的,以此类推。然而,我想指出两件事:1)我并不是在这里描述自然规律,而是简单地描述社区的一种趋势,它可能会影响某些架构和优化器的共同进化;事实上,我有一些证据来支持这一说法。
如果我说的是真的,我们可以预期 Adam 在深度神经网络方面会非常出色而在其他方面则会非常差。这确实发生了!例如,众所周知,Adam在非深度神经网络的简单凸和非凸问题上表现很差,参见下面的实验(Vaswani et al., 2019):
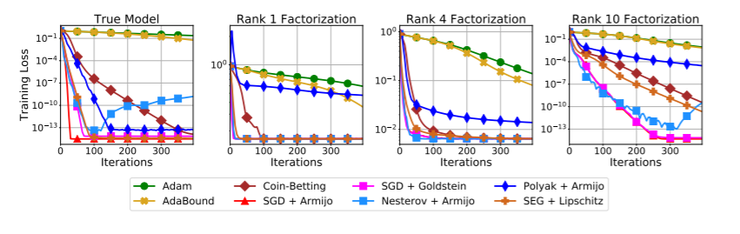
似乎当我们远离深度神经网络的特定设置,以及它们对初始化的特定选择、特定权重的比例、特定的损失函数等,Adam 就失去了它的自适应能力,它神奇的默认学习率必须再次调整。请注意,您总是可以将线性预测器写成单层神经网络,但 Adam 在这种情况下也不太好用。因此,在深度学习中,所有特定的架构选择可能已经进化到让 Adam 工作得越来越好,而上述简单的问题并没有任何让 Adam 发光的好特性。
总的来说,Adam 可能是最好的优化器,因为深度学习社区可能只在架构/优化器的联合搜索空间中探索一小块区域。如果这是真的,对于一个脱离凸方法的社区来说,这将是一个讽刺,因为他们只关注可能的机器学习算法的一个狭窄区域,它就像 Yann LeCun “写道:“在路灯下寻找丢失的车钥匙,却发现钥匙丢在了别的地方。”
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

